浅谈微服务架构、大数据技术
1 微服务架构现状及原理
目前 SpringCloud、Dubbo等微服务主流开发框架盛行, Spring Cloud 也被开发者认为是最好的开发框架;越来越多的单体应用架构向微服务化转变。微服务化与容器技术相辅相成,容器技术的成熟为微服务提供了得天独厚的客观条件。轻量化的容器是微服务的最佳运行环境,微服务应用在容器环境下等到了运维效率的提升。
其中: 微服务化主要是对单体应用功能解耦。
1.1 微服务架构优点
通过分解单体应用为多个微服务的方式降低了单体应用的复杂度。每个服务通过rpc或者消息驱动的api定义清楚边界。微服务模式为单体式编码方式很难实现的功能提供了模块化的解决方案,使单体服务很容易开发理解和维护。 微服务架构模式使得每个微服务独立部署,开发者不再需要协调其他服务部署对本服务的影响。在此模式下可以加快部署速度,降低服务的耦合。
1.2 微服务架构缺点
1、微服务应用是分布式系统,复杂度高。多个微服务也会存在分布式事务、数据一致性等问题,对业务开发提出了更高的挑战。
2、使用微服务处理大数据的计算在数据聚合数据分片等方面处理难度高。微服务间的大量的通信IO会成为计算瓶颈。在数据量不断增大,性能瓶颈愈加明显。
1.3 微服务架构总结
微服务化的重点是对业务应用的拆分,功能解耦。但并不解决业务应用本身如大规模数据计算等问题。业务拆分对于OLTP型系统较适合(容错、负载均衡、可扩展性)但是对于计算密集型任务,处理能力不足。尤其与集群计算对比不足更加明显。
2 大数据处理框架现状
目前开源分布式大数据计算引擎有很多选择,批处理如 Spark, Hive, Pig, Flink 等,流计算如 Storm, Samza, Flink, Kafka Stream 等。如果需要同时支持流处理和批处理,有两种主流的选择:一个是Apache Spark,一个是Apache Flink。
2.1 Spark介绍
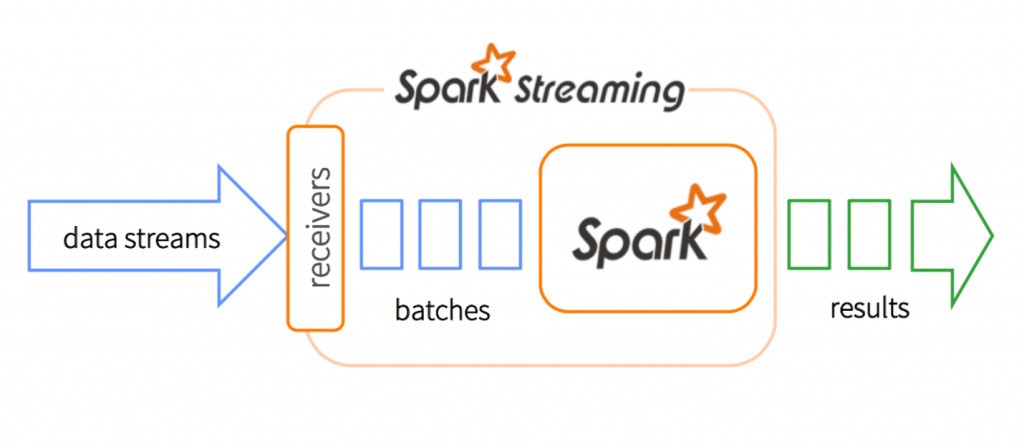
Apache Spark(图1-1)提供了一个统一的引擎,它支持批处理和流处理工作负载,而其他系统要么具有仅用于流式传输的处理引擎,要么具有类似的批处理和流式API,但内部编译到不同的引擎。Spark将流数据分离成微批(micro batches),这意味着它接收数据并在spark的工作节点中并行缓冲它。这样可以实现更好的负载平衡和更快的故障恢复。每批数据都是一个弹性分布式数据集(RDD),它是Spark中容错数据集的基本抽象。
2.2 Flink介绍
Apache Flink(图1-2)是一种最新的大数据处理工具,以大规模的分布式系统上的低数据延迟和高容错性快速处理大数据而闻名。它的主要特点是能够像风暴一样实时处理流数据,主要是一个看起来像批处理器的流处理框架。它针对通过优化连接算法,操作符链接和重用分区而实现的循环或迭代过程进行了优化。
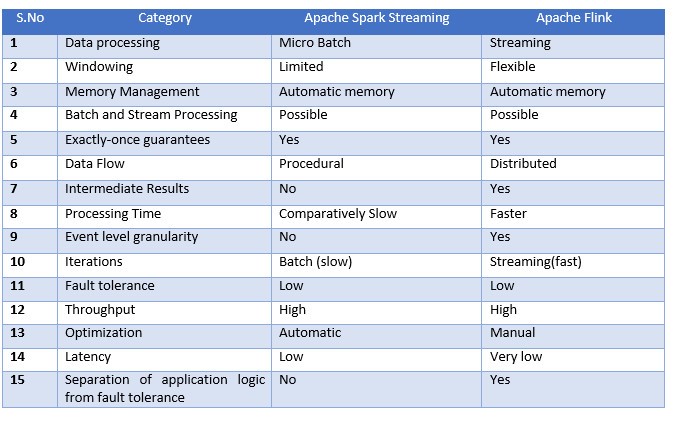
2.3 Spark/Flink对比
这两个系统都旨在构建单一平台,您可以在其中运行批处理,流式处理,交互式,图形处理,ML等。虽然Flink提供事件级粒度,而Spark Streaming不提供,因为它是一个更快的批处理。由于批次的固有性质,在Spark流媒体中对窗口的支持非常有限。Flink通过更好的窗口机制来管理Spark流。Flink允许窗口基于处理时间,数据时间,没有记录是可以指定。与Spark相比,这种灵活性使flink流API非常强大。
Spark Streaming遵循过程编程系统,而Flink遵循分布式数据流方法。 因此, 每当Flink需要中间结果时,广播变量用于将预先计算的结果分发到所有工作节点。
Spark Streaming和Flink之间的一些相似之处是完全一次保证(正确的结果,也在失败的情况下),从而消除任何重复,并且与Apache Storm等其他处理系统相比,两者都提供了非常高的吞吐量。此外,两者都提供自动内存管理。
例如,如果您需要计算具有特定时间间隔的商店的累计销售额,那么批处理可以轻松完成,而是在创建警报时,当值达到其阈值级别时,可以很好地解决这种情况通过流处理。
现在让我们深入分析一下Spark Streaming 和Flink的功能:
 (图片来源: Linkedin)
(图片来源: Linkedin)
2.4 小结
Spark在批量数据处理方面有很多优势,它是一个非常成熟和完整的批处理框架,同时也能满足很多流处理的需求。Flink可以处理批处理,但现阶段它与同一联盟中的spark还有一定的差距。
对于行情落库的场景,Spark能够高效,高并发,异步的将行情落库,目前我们内部初步测试,在性能和延时上Flink和Spark差别并不大。