CPU Cache 架构
1 SMP (Symmetric Multi-Processor)
对称式多处理器 (SMP) 是一种计算机系统结构。
多处理器结构有两种:
(l) 对称 —— 多个处理器都是等价的,线程每次受调度运行时都可以动态选择在任何一个处理器上运行。
(2) 非对称 —— 处理器的结构、能力、所处的部位、和作用都各不相同,不同的线程只能在特定的处理器上运行。
通用 CPU 一般都是对称多处理器,生活中常见的CPU有 Intel Core 和 AMD 的CPU。
现代CPU朝着多核,多线程的方向发展。因为内存的存取速度远远跟不上CPU的执行速度,
所以引入了L1, L2,L3 级cache,L1 cache最小,分为指令cache和数据cache两种,两者都有32 Kbytes,他的存取速度是最接近于寄存器的。L2 cache一般有 256 Kbytes, L3 Cache 有 8 Mbytes。
如下图:(其中 x6 表示有6个硬件core)
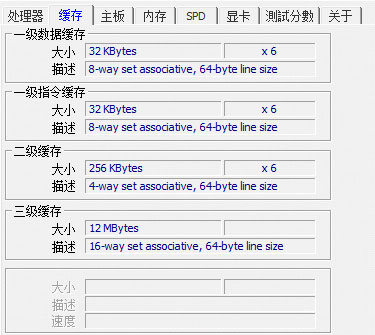
随着物理core的集成工艺不断提升,市场上的服务器CPU 能够看到有32 core,甚至 64 core。 这时候 SMP 架构的劣势就显现出来了,当发生cache miss时,多个 core 会同时向一个 RAM 请求数据。 这样主存就有大量的竞争压力,为了提高RAM 的访问效率,NUMA架构就出现了。
2 NUMA (Non Uniform Memory Access Architecture)
非统一内存访问(NUMA), NUMA 把一台计算机分成多个节点(node), 每个节点内部拥有多个CPU, 节点内部使用共有的内存控制器,节点之间是通过互联模块进行连接和信息交互。 如下图所示:
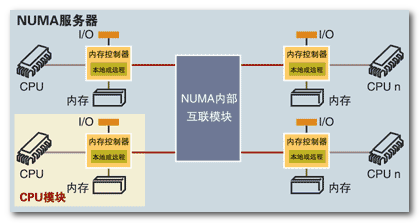
当发生 cache-miss, 优先访问本地的记忆体(RAM),然后才通过NUMA内部的互联互通模块访问远端的NUMA节点。
当然访问远端的NUMA 延迟相对会大一些。
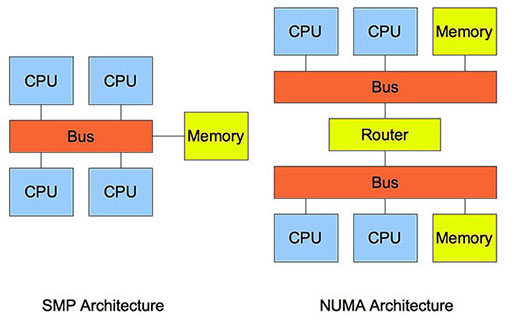
3 SMP vs. NUMA
4 CPU 缓存一致性
因为在多核CPU时代,CPU有“缓存一致性”原则,也就是说每个处理器(核)都会通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了。如果过期了,则失效。比如声明 volatile,当变量被修改,则会立即要求写入系统内存。
5 总结
NUMA将 Core 和 Memory 细分为多个Node, 每个Node可以简单看成一个 SMP 架构。
参考
扩展阅读
1) Intel Core cache
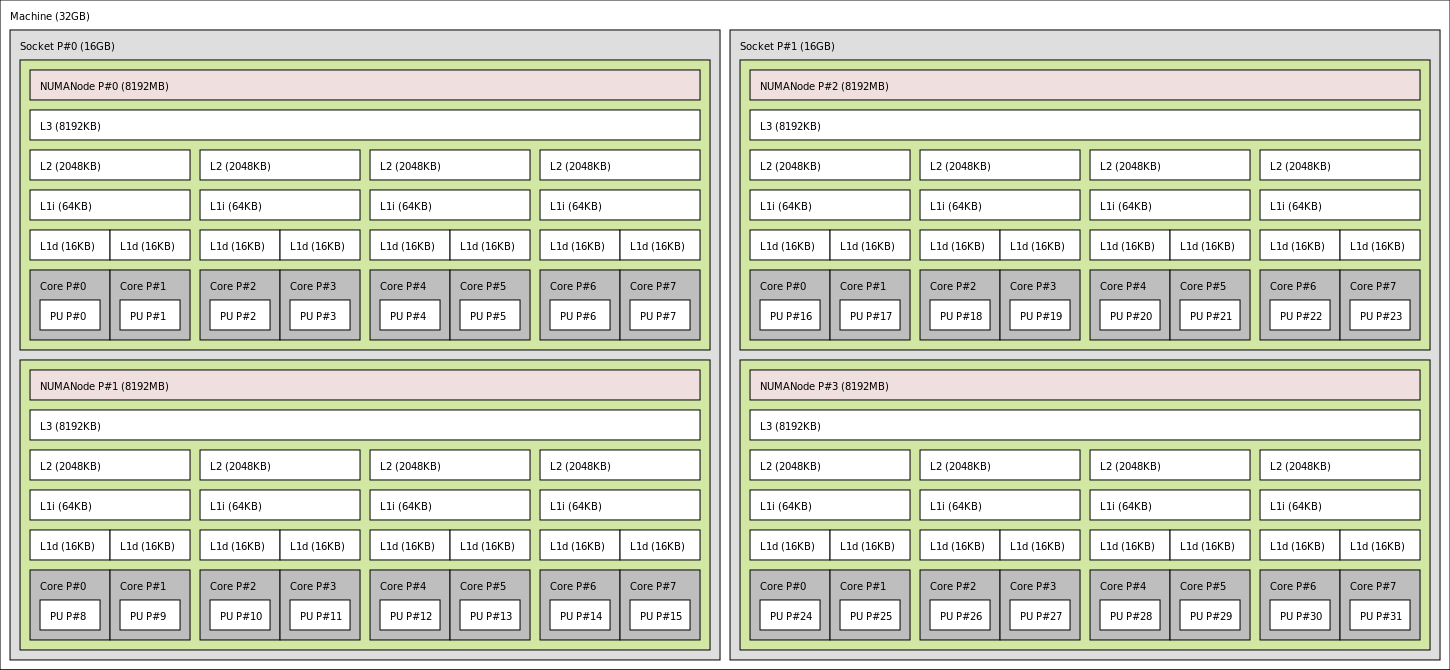
看一个典型的 Intel-Core-i7-cache 的架构图:
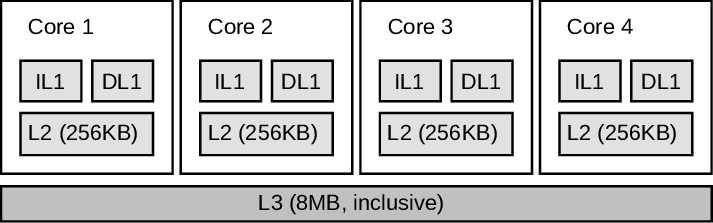
在 SMP 的3层cache 结构中:
(1) L1 cache 分为2类(指令和数据),只为一个core提供cache;
(2) 每个核心都有自己的 L1缓存 和 L2缓存, 但三级缓存却是一颗 CPU 上所有核心共享的。
(3) 访问缓存要比内存快很多:
- 一级缓存只需要 4~5 个时钟周期;
- 二级缓存大约 12 个时钟周期;
- 三级缓存大约 30 个时钟周期;
- CPU 访问一次内存通常需要 100 个时钟周期以上。
(对于 2GHZ 主频的 CPU 来说,一个时钟周期是 0.5 纳秒)
2) 超线程技术
超线程技术(Intel Hyper-Threading),就是使用特殊的硬件指令,把一个Core当成两个逻辑core 来使用, 在OS看来,逻辑处理器和实体处理器没有区别,因此OS会把工作线程分派给"2颗" 处理器去并行处理。
虽然采用超线程技术能够同时执行两个线程,但它并不像两个真正的CPU那样(每个CPU拥有独立的资源)。 当两个线程都需要某一临界资源时,其中一个线程需要暂时停止,直到这些资源闲置,因此超线程并不等于两颗CPU。
超线程技术只需要增加很少的晶体管数量, 就可以在多任务的情况下提供显著的性能提升, 比再添加一个物理核心划算的多,所以再新一代主流的CPU上多采用HT技术。