Seastar 之核间通信 (2)
1 0核和任一个核通信
Seastar 使用 eventfd 进行核间(线程间)通信,因为每个线程使用内核API sched_set_affinity(),绑定一个 SMP 的 core,所以我们这里称之为核间通信。
Seastar 创建了一个 N*N 的 event_fd 矩阵,每个单元格上两个event_fd,每一行event_fds由一个线程(Core)管理。
也就是说每个线程的 epoll 上,一共需要侦听 2N 个 event_fd。
示意图如下:
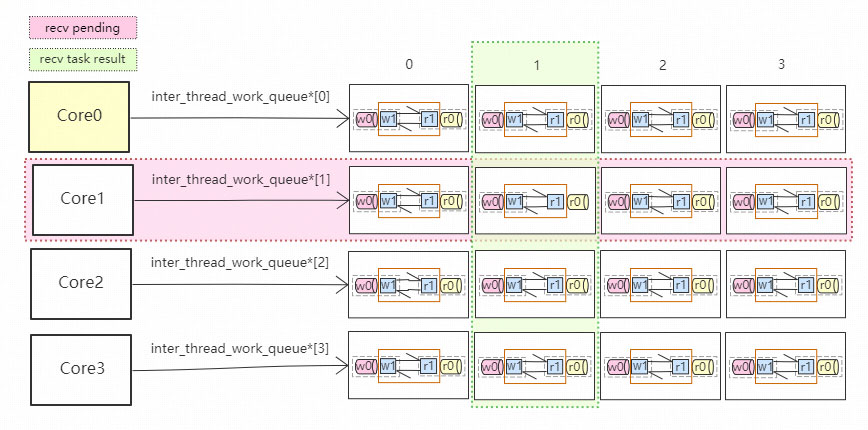
每一个Core K, 负责矩阵的第K行, 第K列。
具体表现为:
1 从第K行所有的 w1 上接收待执行的task, 执行完后写入对于的 r1;
2 向第K列的 w0 上发送核间task, 同时从第 K 列的 r0 上接收task执行结果;
干事做事很在行, 列位都是领导。
第 K 行是CoreK自己要干的活儿; 而在第K列, CoreK可以给其他的core派活干。
这里每一对 (w0, w1) 在内核中的文件指针,都指向同一个文件表, 他们的关系是:w1=dup(w0), 同理(r0, r1)也是这样的。
详细解释一下这个矩阵:
(1) w0 用于其他 core 主动发送 task给当前 core;
(2) w1 收取w0上的, 并在当前core上执行,然后把执行结果写入r1;
(3) r0 core-0 侦听所有r0 eventfd,然后执行上面的task;
注意 core-0 会接收所有 r0 的 readable 事件。
总结一下: 目前这个版本值支持 core-0 向其他core发送任务,当其他core执行完一个task,就把后续任务放入complete队列,并通知r0将其处理。
这就实现了一个 core 间 task 转发,请细细品味。
2 任意两个核之间通信
上面我们理解了Core-0 向其它核如何发送消息,并且其他核执行完,把结果返回给Core-0。
细心的你一定发现,Core-0和其他Core 已经不对称了,为啥所有的应答,最后都回到Core-0,不应该是原路返回给请求方吗?
是的,简单起见,我们先简化一下上面的消息矩阵:
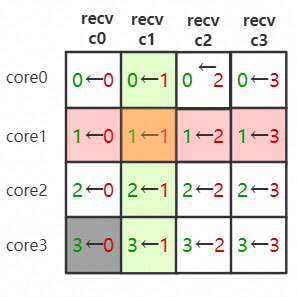
其中每个单元格的坐标(x,y), 表示 Core-y 向 Core-x 发送核间消息, 之后该消息最后要回到Core-y,那么只要 Core-y 把矩阵中列号为 y 的r0(fd)都加入自己的epoll,就可以完美的收到任务完成的通知。
因为核间通信要做到双工,返回消息应答时,按照上图的箭头发方向即可。
3 总结
我们来总结一下:
(1) Seastar构造了一个 eventfd 的方阵,将每个单元格记做(x,y),它仅仅只用于核 x 向核 y 发送消息,并将执行完的结果返回给核x。
(2) 每个单元格中有2个eventfd(w0, r0), 这两个fd都还有一个分身(w1,r1);
(3) (w0,r0) 仅在线程x中使用,(w1,r1)仅在线程y中使用,即保证 fd 不会跨线程使用;
(4) 完整的事件通知流为:w0(write) -> w1(recv) -> r1(write) -> r0(recv);
QA
Q: 在上文中我们提到w1=dup(w0),为什么要dup出一个新的w1 这个fd呢?
A: 分离出两个fd为了读写分离,因为读和写是在两个不同的线程。
Q: 假如不dup出一个新的w1,会有什么问题?
A: 同一个fd加入两个线程(不同的epoll红黑树中),关联两个不同的struct epoll_event,而且一个线程只关心读,另外一个线程只关心写;直觉上是没有冲突的。
也就是说,只是用一个fd,保证读写分离的情况下是没问题的! 因为就算分离出2个fd,他们背后还是指向同一个内核文件指针,读写事件都会对2个 fd 产生作用!
《全文完》
文末尾给出了《Seastar 源码之美》系列文章的目录,希望你能在这个列表里找到自己感兴趣的内容。